Computação em nuvem se refere, essencialmente, à ideia de utilizarmos, em qualquer lugar e independente de plataforma, as mais variadas aplicações através da Internet com a mesma facilidade de tê-las instaladas em nossos próprios servidores. Um dos tipos de serviços que podem ser oferecidos sobre essa plataforma é o armazenamento de dados em nuvem. Zeng et. al introduz o armazenamento de dados em nuvem como um dos serviços que fornecem recursos para armazenamento e serviços em servidores remotos baseados na computação em nuvem. Um sistema para armazenamento em nuvem pode ser desenvolvido em cima da arquitetura peer-to-peer (P2P), para tirar proveito desse modelo, por exemplo, para evitar gargalos de forma eficiente e pontos únicos de falha. Além disso, esses sistemas podem usar o espaço disponível nos peerspara armazenar dados, devendo, para isso, levar em consideração atributos como replicação de dados, segurança, seleção de peers com alta disponibilidade, etc. [Machado, 2013].
Desse cenário, surge a necessidade da busca de conteúdo dos arquivos, de forma que permita que sejam realizadas buscas em sistemas de armazenamento em nuvem implementados sobre redes peer-to-peer. Para tal, determinados peers na rede podem atuar como servidores de busca, e fornecer aos outros peers serviços de indexação de conteúdo de arquivos e busca.
Essa pesquisa tem como objetivo principal propor uma abordagem eficiente para o balanceamento de carga de servidores de busca, em sistemas de armazenamento de dados P2P com JXTA, implementada sobre a plataforma de nuvem. O balanceamento de carga será utilizado visando às ações de indexação de conteúdo de arquivos, busca de arquivos e replicação de índices.
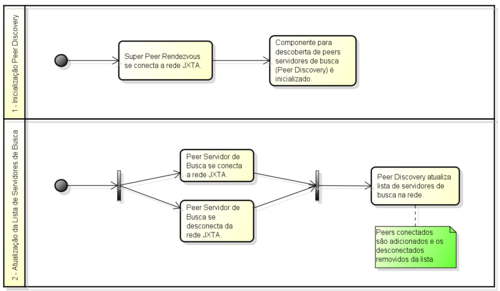
Tendo em vista a necessidade de realizar um balanceamento distribuído, o balanceador estará situado no super peer rendezvous, pois todos os peers na rede conectam-se a ele, possibilitando assim que o balanceador tenha sempre sua lista de peers servidores de busca atualizada. Essa lista com os peers conectados será fornecida por um componente responsável pela descoberta de peers servidores de busca.
Quando um super peer se conecta a rede, o mesmo inicializa o Peer Discovery, que é o componente responsável pelo descobrimento dos servidores de busca na rede. Periodicamente, o Peer Discovery atualiza a lista de servidores de busca, adicionando novos e removendo os desconectados da rede, para ser utilizada pelo Load Balancer. Um peer, ao se conectar a rede JXTA, publica um advertisement informando qual é o seu tipo (cliente, servidor, servidor de busca, etc.). Se o peer recém conectado a rede for do tipo servidor de busca, o mesmo é descoberto e adicionado a lista de servidores de busca do Peer Discovery. A Figura 1 demonstra o fluxo da descoberta e atualização da lista de servidores de busca pelo Peer Discovery.
As próximas etapas do projeto são:
- De posse da lista de servidores de busca disponíveis na rede, definir a estratégia e componente para o balanceamento de carga.
- Definir e utilizar métricas para saber se um determinado peer servidor de busca está balanceado.
- Replicação e mesclagem de índices de conteúdo de arquivos.
- Os testes para validação ainda serão implementados e executados dentro de um sistema real de armazenamento de dados em nuvem, e medirão, através de métricas que indiquem o nível de balanceamento, a distribuição da carga realizada pela abordagem proposta. A replicação dos índices de busca de arquivos e mesclagem dos mesmos também serão testadas nessa etapa.
Qualquer informação sobre o projeto entre em contato com a equipe pelos endereços:
- Jean Brasil: jlbfc (at) cin dot ufpe dot br
- Vinicius Garcia: vcg (at) cin dot ufpe dot br