Motivação: Com os últimos acontecimentos divulgados ao público sobre o caso Snowden [http://www.theguardian.com/world/2013/jun/09/edward-snowden-nsa-whistleblower-surveillance], o tema privacidade vem assumindo seu lugar nas discussões em diversas áreas do nosso cotidiano.
Sabemos que, desde transações online que realizamos até nossos dispositivos móveis, a forma [nada sutil] como nos expomos na famigerada Web 2.0 - onde nós mesmos criamos o conteúdo (que eventualmente acaba revelando mais de nós mesmos do que gostaríamos) - os próprios serviços que utilizamos “gratuitamente”, nos quais a moeda de troca acaba sendo nossos dados, nós acabamos abrindo mão de um recurso que, até pouco, alguns de nós sequer davam alguma importância.
O fato é que ‘eles’ [quem quer que sejam] sabem de nós. E pior que isso: tamanha nossa dependência da existência online, que somos vítimas - quase que voluntárias - de um monitoramento contínuo, que é um prato cheio para as corporações que sabem o que fazer com isso.
Tudo que é monitorado sobre cada indivíduo vai parar na cloud (formando um big data sobre cada um de nós). Fotos, dados pessoais, histórico de compra, histórico de localização, quem são os familiares, assuntos de interesse e assim por diante. E uma vez na cloud, não há como recuperar esses dados de volta. Ninguém pode te garantir que isso pode ser ou será feito. Além disso, com técnicas modernas de mineração e análise de dados, as empresas interessadas podem saber mais sobre uma pessoa do que ela mesma.
Recentemente foi publicado no New York Times [1] que, baseado em hábitos de compra, a Target - uma grande varejista americana - atribuía um índice de predição de gravidez a cada cliente, baseado na análise de dados históricos de mulheres que haviam manifestado seu interesse por produtos para recém-nascidos. Os estatísticos da Target descobriram alguns padrões de consumo para esse perfil específico de cliente que permitia prever a chance da mulher estar grávida e para quando seria o bebê.
Certo dia, o pai de uma adolescente foi até uma loja da Target para questionar o gerente do porque sua filha tinha recebido cupons e propagandas de produtos para bebê. Um tanto surpreso, o gerente se desculpa pelo ocorrido. Dias mais tarde, o novo vovô liga para a loja para se desculpar com o gerente, dizendo que algumas coisas tinham ocorrido em sua casa sem que ele tivesse conhecimento.
Sem sequer usar nada mais complexo que isso, dá pra sutilmente “manipular” suas ações futuras, baseado em suas ações passadas e de outras pessoas com perfis similares ao seu. Esse é o que eu considero o efeito mais nocivo da perda de privacidade: o desequilíbrio entre o que você sabe sobre você e o que as empresas sabem sobre você.
Transpondo tudo isso, para o contexto de uma cidade inteligente, onde o objetivo principal é melhorar a qualidade das pessoas, não tem como fazer isso sem saber delas. Logo, as pessoas precisam ser monitoradas de alguma forma, direta ou indireta. Além do mais, a provisão de serviços inteligentes no contexto urbano vai depender de diversos provedores de serviços, para diferentes finalidades. Ou seja, assim como acontece na internet hoje, nossos dados estarão novamente em mãos alheias, portanto, antes que isso se torne real para a grande maioria da população, precisamos de alguma solução que nos permita tirar proveito da massa de dados que existe sobre nós, além de assegurar um dos substratos necessários para o processo de smartening das nossas cidades.
Quanto à privacidade, no estágio atual, a literatura científica aponta para um cenário onde a manutenção de dados vai girar em torno do usuário, do indivíduo (ao contrário do modelo atual, que gira em torno do próprio dado)**, **assim, haveria controle sobre o ciclo de vida de seus dados pessoais (coleta, gerenciamento e uso até sua eventual exclusão), mesmo que estes estejam sob controle de grandes corporações, além de fornecer o mínimo de dados possível quando for utilizar algum serviço (minimização de dados) e, quando for fazê-lo, explicitar seu consentimento de exposição baseado em informações relevantes sobre provedor de serviço, as características do serviço a ser consumido (dados necessários e a informação esperada como saída), bem como do risco assumido ao expor os dados em questão. Essas informações permitiriam uma tomada de decisão de exposição de dados baseada em parâmetros concretos sobre o referido contexto.
Este é o objetivo da minha pesquisa, aplicar os conceitos explicitados no parágrafo anterior, na forma de um framework de gestão de privacidade para dados pessoais, ao contexto de cidades inteligentes, integrado a uma arquitetura subjacente, contemplando a provisão/utilização de serviços num ambiente urbano plenamente ubíquo e pervasivo.
[1] Hill, K. (2012). How target figured out a teen girl was pregnant before her father did. http://onforb.es/180SlGT. “[Online] Available: November 12, 2013”
A proposta: Inicialmente realizamos um levantamento sobre mecanismos de privacidade propostos para diferentes contextos inteligentes. Anteriormente, havíamos feito uma revisão sistemática especifica para arquiteturas de cidades inteligentes [http://dl.acm.org/citation.cfm?id=2480688] e vimos que o assunto não era devidamente focado nos trabalhos encontrados. Assim, ponderamos que seria melhor abranger o escopo do levantamento para ambientes inteligentes (smart homes, smart grid, smart health, etc.), já que cidades inteligentes essencialmente compreenderiam todos eles.
Foram estudados 28 trabalhos, dos quais foi extraído um conjunto de requisitos. Desse conjunto de requisitos, o subconjunto que melhor representava o paradigma centrado no usuário, foi selecionado para fazer parte da proposta. A saber:
- Degradação de dados, na qual determinado dado torna se inútil com o passar do tempo devido à perda de precisão;
- Sensibilidade de dados, que mensura quão sensível determinado dado é, ou em outras palavras, o risco de exposição desse dado;
- Confiança sem interação prévia, que aproxima a reputação de uma entidade provedora de serviço baseada em outra similar (o conceito de similaridade no contexto deste trabalho será definido mais adiante);
- Múltiplas identidades, na qual cada identidade é composta por um subconjunto de atributos de determinado indivíduo, assim, para consumir determinado serviço, apenas a identidade necessária será exposta;
- Minimização de dados, como umas das consequências diretas das múltiplas identidades, onde apenas os dados essenciais são fornecidos; nada mais que isso.
- Controle/Feedback para o usuário, este requisito compreende o ciclo de vida dos dados de um indivíduo estarem sob seu controle, bem como sua experiência no consumo de um serviço ser levada em consideração sempre que houver novas interação.
- Especificação de preferência, aqui tanto provedores de serviço, quanto indivíduos consumidores de serviço podem especificar as preferências sobre as quais a interação vai ocorrer. Quando as especificações de preferências podem ser feitas por parte do usuário, a literatura dá o nome de featurization.
O framework de privacidade:
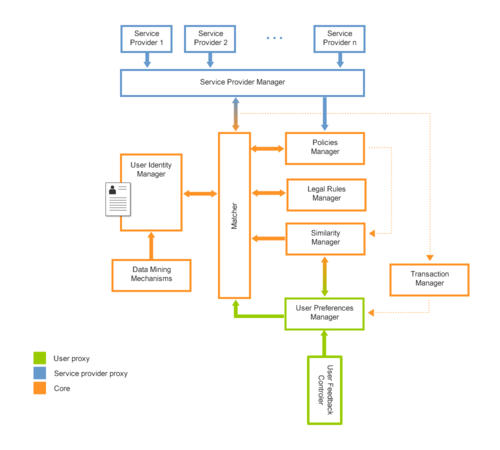
**Services Provider Manager: **Responsável por gerenciar as informações de identificação dos provedores de serviço e os serviços que eles fornecem.
**Identity Manager: **Responsável por gerir os atributos primitivos (nome, data de nascimento, endereço, etc.) de cada indivíduo e gerar a identidade mais adequada para o consumo de algum serviço.
Policies Manager: Gerencia as policies dos serviços (e seus respectivos níveis de proposição de valor) providos dentro do framework.
**Legal Rules Manager: **Permitir que as questões legais sobre a exposição de dados seja contemplada pelo framework.
Núcleo Cognitivo:
- Similarity Manager: Responsável por determinar a similaridade entre diferentes provedores de serviço.
- Preference Manager: Responsável por permitir ao usuário impor suas preferências na forma como seus atributos serão expostos, quando, como e por quanto tempo.
- Feedback controller: Responsável por permitir ao usuário manifestar sua opinião sobre serviços utilizados;
- Transaction Manager: Responsável por manter o histórico de interações, a fim de fornecer informações para futuras interações.
**Matcher: **Responsável por estabelecer o consenso entre o nível de proposição de valor do serviço a ser consumido (benefício), o Identity Manager (que dados serão expostos)e o _Preferences Manager _(sob que condições).
A ideia aqui é que, quanto menor a exposição e maior a proposição de valor, melhor o nível de privacidade e mais efetiva a interação.
O estágio atual do projeto trata-se de definir o método de avaliação que poderá ser empregado. Ainda estamos na dúvida de que abordagem aplicar, já que os requisitos são implementados basicamente através de formulas matemáticas, com uma justificativa mais semântica que formal.
Texto escrito por Welington Silva