Com o aumento da capacidade das unidades de armazenamento, aumentou também a demanda por utilização. Em 2000, a estimativa da indústria era de um aumento anual entre 50% a 100% dessa demanda, estimativa essa que se consolidou. Nos últimos anos esse aumento atingiu um valor anual de mais de 50% (KAPLAN, 2008).
A Figura 1 mostra dois gráficos sobre a demanada por armazenamento entre 2006 e 2011. Um deles demonstra o forte crescimento da demanda por armazenamento nas empresas, e o segundo, exibe a queda de 20% ao ano no preço por Gigabytes.
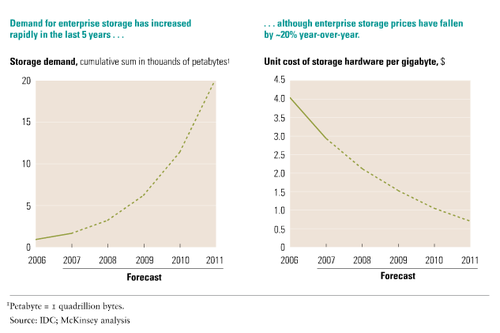
Figura 1 - Aumento da demanda e redução do custo de hardware de armazenamento (KAPLAN, 2008)
A indústria de TI passou a apostar em sistemas de armazenamento de dados distribuído nos últimos anos. Empresas como Amazon, Google, Microsoft e Salesforce começaram a investir em centros de armazenamentos de dados na nuvem (Cloud Storages), espalhados pelo mundo, com garantia de redundânica e tolerância à falhas.
Com esse aumento da demanda por armazenamento, a utilização de técnicas de compressão de dados se torna um fator chave para redução dos custos. A deduplicação de dados é um técnica de compressão de dados que armazena uma única cópia de dados redundantes, eliminando as outras do sistema de armazenamento. A deduplicação pode ser feita à nível de arquivo completo ou de bloco.
A utilização de deduplicação de dados em sistemas de armazenamento em nuvem dá uma grande vantagem à empresa que fornece o serviço. Com a utilização da deduplicação, a empresa poderá vender para os cliente mais espaço de armazenamento do que ela tem fisicamente.
Os principais sistemas distribuídos de deduplicação de dados são feitos para serem executados em clusters ou em nós simples, alguns deles usam framework para processamento distribuído de dados, como Hadoop, por exemplo, mas há uma falta de pesquisa envolvendo sistemas de deduplicação para ambientes de armazenamento de dados construídos com arquitetura peer-to-peer e utilizando computadores pessoais para armazenar esses dados. Apesar de grandes empresas como a EMC, Symantec, NetApp, entre outras, investiverem em sistemas para deduplicação de dados, detalhes importantes não são divulgados por questões comerciais.
Um dos objetivos do projeto foi a criação de algoritmos encapsulados dentro de componentes de software com interface de integração para os sistemas distribuído de armazenamento de dados. Foram desenvolvidos dois algoritmos, um mais simples, em que o arquivo a ser analisado para deduplicação é todo carregado para a memória principal, e um outro, que foi desenvolvido para dar suporte à arquivos sem limite de tamanho. Esse segundo algoritmo divide o arquivo em partes de tamanho definido no parâmetro da interface de comunicação, e processa o arquivo em partes, permitindo assim que arquivos maiores do que a memória sejam processados.
Os dois algoritmos foram inspirados no rsync, que é o algoritmo para otimização de transferência de arquivos entre computadores utilizado pela ferramenta rsync, desenvolvido por Andrew Tridgell and Paul Mackerras. O rsync usa um um tipo de checksum (hash de 32 bits), chamado de rolling checksum, que tem a propriedade de ser calculado de forma pouco custosa quando o cálculo do checksum da janela anterior já tiver sido feito, por exemplo, se o checksum do bloco de bytes Xk … Xl já for conhecido, obter o do bloco Xk+1… Xl+1 é mais rápido. A utilização dorolling checksum torna viável, por tornar a operação menos custosa, o cálculo de hashes para todos os possíveis chunks, de um determinado tamanho especificado, formados a partir de um arquivo.
O algoritmo para processamento do arquivo em partes, tem uma abordagem diferente da forma como o rsync e o algoritmo mais simples fazem. O rsync e o primeiro algoritmo, percorrem o conteúdo binário do arquivo à procura de um conjunto sequencial de bytes que seja igual à um chunk conhecido. Com o segundo algoritmo, essa comparação é feita de uma forma reversa, primeiro é calculado o valor da função de hash em um conjunto sequencial de dados do arquivo em que se quer achar conteúdo duplicado, em seguida esse valor é comparado à uma estrutura de dados organizada como um map<hash32, map<md5, id> >, que tem as informações de todos os chunks para comparação. Caso encontre algum chunk que tenha o mesmo hash, é feita uma busca do md5 da sequência de dados no Map que é o valor da função hash32 encontrada. Isso possibilita a comparação sem que seja preciso ter todo o conteúdo do arquivo na memória principal.
Também foi desenvolvido um sistema para gerenciamento de arquivos com base fundamental no Cassandra, para funcionar como um sistema de armazenamento, e assim facilitar o teste da ferramenta e validação do trabalho, como para os pesquisadores que se interessarem opr analisar a trabalho desenvolvido. Os testes em um ambiente distribuído real estão planejados para início de abril.
Todo o conteúdo produzido neste projeto estará disponível em breve no endereço: https://github.com/paulofernando/dedupeer
| Para mais informações sobre o projeto, acesse o site oficial http://dedupeer.com, ou entre em contato com Paulo Fernando, Vinicius Garcia ou Silvio Meira, pelos respectivos endereços: (pfas | vcg | slrm) (at) (cin.ufpe.br). |
KAPLAN, J. M., ROY, R., AND SRINIVASARAGHAVAN, R. Meeting the demand for data storage. Tech. rep., 2008. Acessado em: Fevereivo de 2012.