A cada dia se produz mais informação e, em muitos casos, essas informações são armazenadas em meios digitais. O tamanho desse “universo digital” cresce de forma exponencial: em 2005, o volume de dados chegou a 130 exabytes; em 2010, superou 1 zettabyte e a previsão é que em 2015 chegue a quase 8 zettabytes. Este “universo digital” citado por Gantz e Reinsel em expande e se torna cada vez mais complexo para processar, armazenar, gerenciar, garantir a segurança e disponibilizar essas informações. Para lidar com esses problemas, segundo o autor supracitado, serão necessárias habilidades, experiência e recursos que rapidamente se tornarão escassos, além de uma nova infraestrutura de Tecnologia da Informação escalável e flexível. Uma opção adequada para este cenário é a computação em nuvem.
Essa grande quantidade de dados gerados pode ser armazenada em nuvem utilizando o conceito de armazenamento em nuvem. Zeng et. al introduz o armazenamento em nuvem como um dos serviços que fornecem recursos para armazenamento e serviços baseados em servidores remotos baseados na computação em nuvem. Segundo o autor, o armazenamento em nuvem está apto para prover serviços de armazenamento a um baixo custo com maior confiabilidade e segurança.
Um sistema para armazenamento em nuvem pode ser desenvolvido em cima da arquitetura peer-to-peer (p2p), como mostrado na Figura 1, para tirar proveito desse modelo, por exemplo, para evitar gargalos de forma eficiente e pontos únicos de falha. Além disso, esses sistemas podem usar o espaço disponível nos peers _para armazenar dados, devendo, para isso, levar em consideração atributos como replicação de dados, segurança, seleção de _peers com alta disponibilidade, etc.
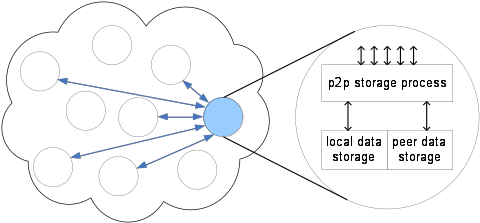
Figura 1: Sistema rodando em nuvem sobre uma arquitetura P2P
Com os dados armazenados em nuvem, também é importante que o usuário possa encontrá-los com facilidade. Com isso essa pesquisa tem como objetivo propor uma abordagem para extração e indexação de conteúdo dos arquivos, de forma que permita que sejam realizadas buscas full-text em um sistemas de armazenamento em nuvem baseado em peer-to-peer. Além disso, essa pesquisa também tem como objetivo investigar uma maneira eficiente para armazenar o índice de busca dentro da arquitetura P2P, de forma que seja possível replicar as informações com facilidade, permita elasticidade, garanta disponibilidadade e, com isso, permitir que as buscas tragar a maior quantidade de resultados relevantes possível.
Para a indexação de arquivos foi utilizado o Apache Lucene, por ser um motor de buscas de alto desempenho escrito em Java. O Lucene contém apenas o núcleo do “motor” de busca. Por isso, ele não inclui um Web crawler ou um parser para diferentes formatos de documentos. Para resolver o problema do parser foi utilizado o Apache Tika, que é um detector e extrator de conteúdo de metadados e texto estruturado, podendo ser utilizado com arquivos de diversos formatos como: HTML, XML, OLE2 e OOXML do Microsoft Office, OpenDocument Format, PDF, ePub, RTF, arquivos compactados e empacotados.
Em um sistema dessa natureza, os arquivos armazenados são quebrados em pedaços menores chamados chunks e armazenados separadamente, ou seja, não existe uma réplica do arquivo que o represente completamente. Devido a essa particularidade, a extração de dados e indexação iniciará paralelamente ao processo de backup e o índice gerado pelo Lucene poderá ser armazenado no próprio peer e/ou em um servidor específico, chamado de SearchServer.
A busca por informações será do tipo full-text, onde o índice possui todas as palavras de seus dados textuais indexadas, portanto consultas procurando por partes de seqüências de caracteres poderão ser processadas de forma muito rápidas.
Com o índice armazenado no próprio peer e no SearchServer, teremos 3 possibilidade de fazer uma consulta ao índice:
- Busca local no próprio índice;
- Busca no índice de outro peer da rede;
- Busca no SearchServer;
Os testes para validação da proposta ainda essa abordagem serão implementados e executados dentro de um sistema real de armazenamento em nuvem e medirão o _precision/recall _do sistema, bem como dados referentes a replicação e elasticidade da solução..
Qualquer informaçao sobre o projeto, entre em contato com a equipe pelos endereços:
- Marco Machado: masm (at) cin dot ufpe dot br
- Fred Durão: freddurao (at) gmail (dot) com
- Vinicius Garcia: vcg (at) cin dot ufpe dot br